
Umi-OCR 是一款免费、开源的光学字符识别(OCR)工具,基于百度飞桨的 PaddleOCR 和 Google 的 Tesseract-OCR 引擎开发,支持离线使用。它专注于高效识别图片中的文字,尤其适用于批量截图、PDF 文档、手写体等场景。Umi-OCR 以其轻量级、易用性和高准确率在文字识别领域脱颖而出,成为个人用户、企业和开发者的理想选择。无论是处理办公文档、学术资料,还是提取游戏字幕或手写笔记,Umi-OCR 都能提供可靠的文本转换解决方案。
软件截图
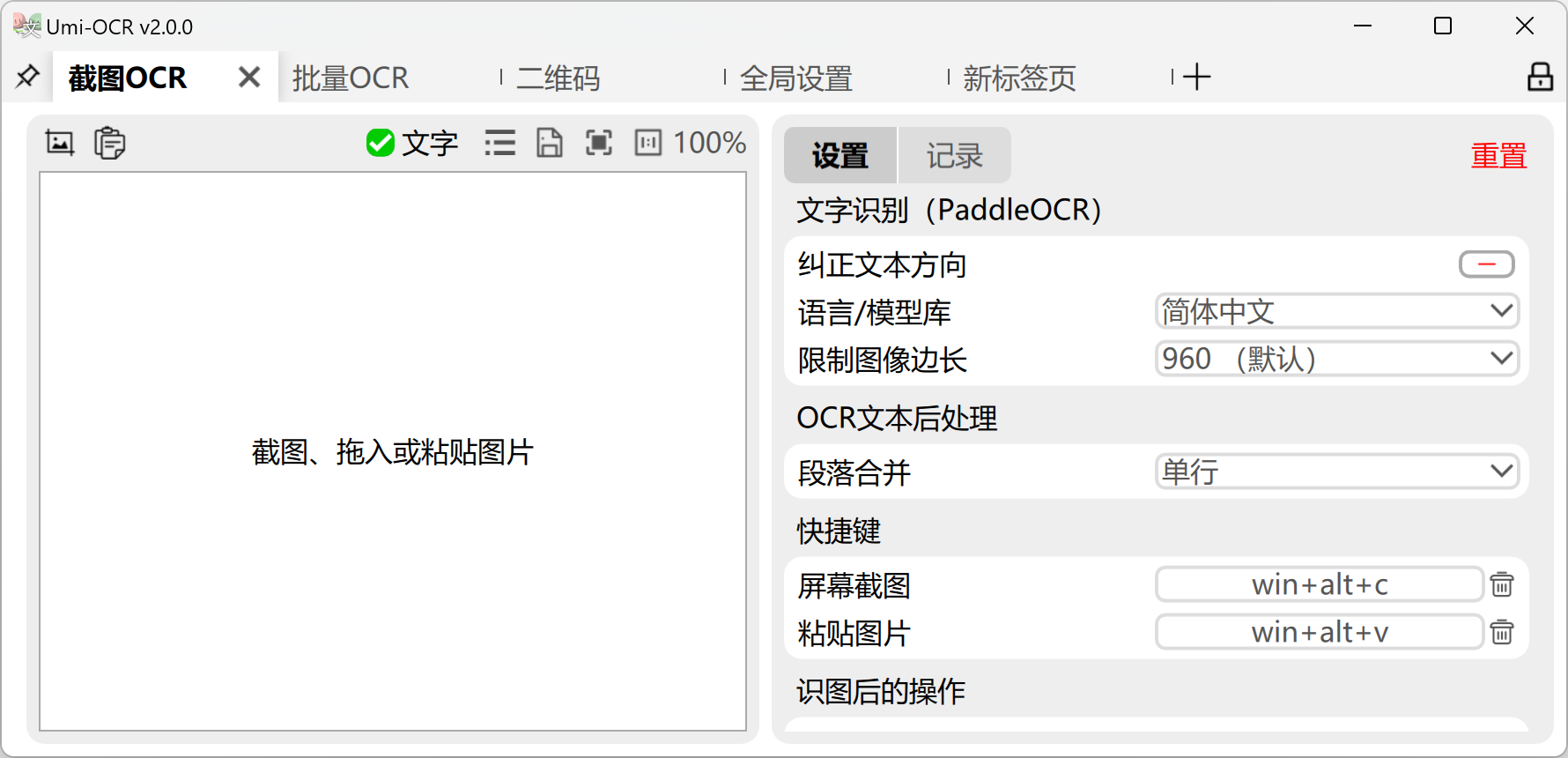
功能特性
-
完全免费开源:Umi-OCR 在 GitHub 上开源,用户可免费使用、修改和优化代码,无需担心版权或费用问题。
-
离线运行:无需联网即可本地运行,保障数据隐私安全,适用于敏感信息处理或网络受限环境。
-
批量处理能力:
- 支持批量导入图片(PNG、JPG、PDF 等格式),自动识别并导出文本。
- 一键截图 OCR:通过快捷键截取屏幕区域,实时识别文字。
-
多语言与高精度识别:
- 内置中文、英文、日语、韩语等多语言模型,支持混合语言识别。
- 结合 PaddleOCR 和 Tesseract 引擎,对印刷体、手写体、模糊文本等复杂场景具备高准确率。
-
灵活的区域控制:
- 可手动框选识别区域,排除水印、按钮等干扰元素,提升识别精度。
- 支持自定义忽略区域模板,适用于固定格式的票据或表单处理。
-
PDF 深度解析:直接导入 PDF 文件,自动解析每页内容并提取文本,保留原始排版结构。
-
文本后处理与导出:
- 智能排版:合并段落、还原缩进,减少人工整理工作量。
- 支持导出为 TXT、Markdown、JSONL 等格式,满足数据分析、文档编辑等需求。
-
高级特性:
- 命令行接口与 HTTP API:便于集成到自动化脚本或第三方应用中。
- 额外功能:二维码识别、数学公式识别(实验性支持)。
下载地址
- 官方仓库:Umi-OCR GitHub 页面
- 免安装版下载:访问 Releases 页面,下载最新版本的 .Zip 包(Windows/Linux 均支持)。
总结
Umi-OCR 凭借其开源、免费、离线运行的核心优势,搭配强大的批量处理能力和高精度识别技术,极大简化了图片与 PDF 中的文本提取流程。无论是个人用户快速转换文档,还是企业处理大量扫描件,Umi-OCR 都能提供高效、安全的解决方案。其灵活的区域控制和多格式导出功能进一步提升了实用性,而开源特性更允许开发者根据需求定制扩展。对于追求效率与隐私的用户,Umi-OCR 是一款值得信赖的 OCR 工具,推荐在办公、学习、科研等场景广泛应用。
工具,基于百度飞桨的 PaddleOCR 和 Google 的 Tesseract-OCR 引擎开发,支持离线使用。它专注于高效识别图片中的文字,尤其适用于批量截图、PDF 文档、手写体等场景。Umi-OCR 以其轻量级、易用性和高准确率在文字...)
工具,基于百度飞桨的 PaddleOCR 和 Google 的 Tesseract-OCR 引擎开发,支持离线使用。它专注于高效识别图片中的文字,尤其适用于批量截图、PDF 文档、手写体等场景。Umi-OCR 以其轻量级、易用性和高准确率在文字...&pics=https://www.xkapps.com/content/uploadfile/202602/143d1770073989.jpg)















这一切,似未曾拥有